1-billion row challenge with Node.js
1-billion row challenge (1brc) is a challenge to process a 12GB file containing 1-billion rows of text.
Each row is formatted as <stationName>;<temperature>\n, and the goal is to aggregate the min, max, and average of each station.
For Node.js, the repository for the challenge can be found here. We will go through the implementation for the baseline approach, understand how it works and work on improving it until we reach a ~30x speedup.
Baseline approach
The repository contains the code for the baseline approach.
The implementation starts with using Node.js built-in to create an interface to read the file line by line:
import * as readline from 'node:readline';
import * as fs from 'node:fs';
const fileName = process.argv[2];
const stream = fs.createReadStream(fileName);
const lineStream = readline.createInterface(stream);
for await (const line of lineStream) {
/* parse the content */
}
Each line is split by the ; character to get the station name and temperature. This information is stored in a Map().
Also, the temperature is multiplied by 10 to avoid potential floating point errors.
const aggregations = new Map();
for await (const line of lineStream) {
const [stationName, temperatureStr] = line.split(';');
const temperature = Math.floor(parseFloat(temperatureStr) * 10);
const existing = aggregations.get(stationName);
if (existing) {
existing.min = Math.min(existing.min, temperature);
existing.max = Math.max(existing.max, temperature);
existing.sum += temperature;
existing.count++;
} else {
aggregations.set(stationName, {
min: temperature,
max: temperature,
sum: temperature,
count: 1,
});
}
}
Finally, the results are printed to stdout following the format described in the challenge.
printCompiledResults(aggregations);
function printCompiledResults(aggregations) {
const sortedStations = Array.from(aggregations.keys()).sort();
let result =
'{' +
sortedStations
.map((station) => {
const data = aggregations.get(station);
return `${station}=${round(data.min / 10)}/${round(
data.sum / 10 / data.count
)}/${round(data.max / 10)}`;
})
.join(', ') +
'}';
console.log(result);
}
function round(num) {
const fixed = Math.round(10 * num) / 10;
return fixed.toFixed(1);
}
On my machine with Apple M4 Pro, this implementation took 5m41.069s to finish the challenge. This will be our baseline to improve upon.
Understanding where the time is spent
We will need some sort of a profiling tool to understand where a lot of the time is spent. I like using Clinic.js Flame for this purpose. It generates a flamegraph from the profiling data, which can be easier to understand than raw profiling data.
To use Clinic.js Flame, we need to install it globally:
npm install -g clinic
Then, we can run the baseline implementation with Clinic.js Flame:
clinic flame -- node src/main/nodejs/baseline/index.js measurements2.txt
Once the process finishes, a browser window will open automatically to show the flamegraph. I generated a smaller measurements2.txt with 500,000 rows
for this process so each iteration loop is faster.
This is the flamegraph generated from the baseline implementation, notice that we are ticking all the boxes at the bottom of the page, so we can see the CPU time spent even in Node.js internals and V8 as well.
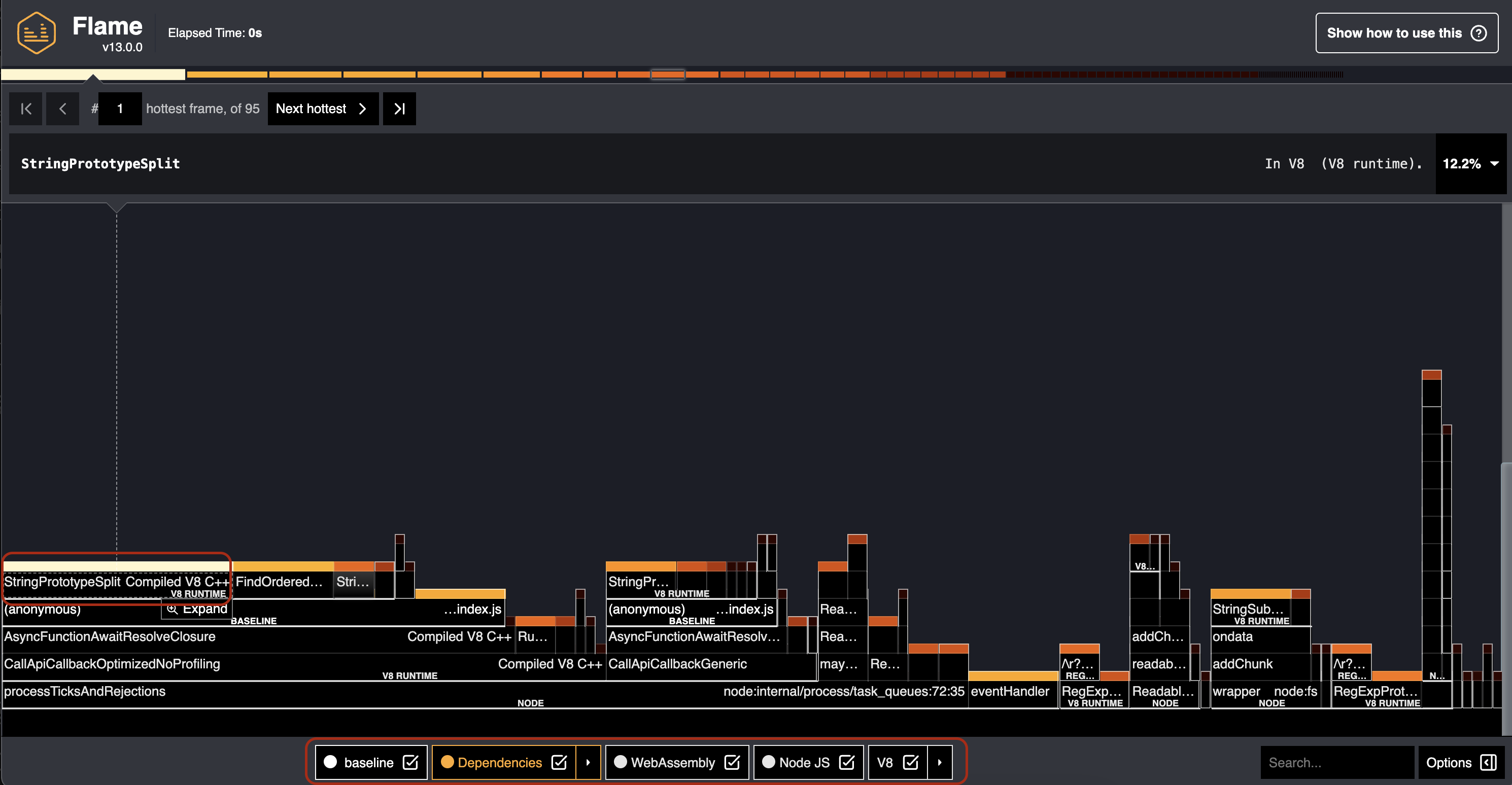
Now that we know how to profile the implementation, we can start working on improving it. There are a lot of things going on in the flamegraph,
but we can usually focus on one thing at a time, do another profiling, and repeat the process. In the flamegraph above, we can see that there is this
block of work that is very hot (called very often) and takes quite a bit of time (the block is quite wide), which is StringPrototypeSplit. We will start our
improving from there.
Improvements
Reducing StringPrototypeSplit calls
StringPrototypeSplit is implemented in the V8 runtime. This means that it is not really feasible to try improving its performance. What we should be looking
to do here is to try reducing or removing the calls to StringPrototypeSplit as much as possible.
It is pretty obvious here that this part of V8 runtime is being called when we split a string.
for await (const line of lineStream) {
const [stationName, temperatureStr] = line.split(';');
/* others */
}
In general, computers are much faster at working with numbers compared to strings. The built-in node:readline module makes things convenient by automatically
reading each lines as strings, but because we want to avoid doing StringPrototypeSplit as much as possible, we will need to find another way to parse the lines.
For starter, we should remove the usage of node:readline to avoid dealing with strings directly. We will start by adding event listeners to the ReadableStream
we get from fs.createReadStream.
const stream = fs.createReadStream(fileName);
stream.on('end', () => {
stream.close();
printCompiledResults(aggregations);
})
stream.on('data', (chunk) => {
// Each chunk is an `Uint8Array` here, or in other words, array of bytes.
})
We will be reading each byte to find the character we are interested in, ; (semicolon) and \n (newline character). The way we are doing this is by:
- Start by looking for semicolon
- Iterate through each byte
- If it is not a semicolon, store the byte somewhere, and continue to the next byte.
- If it is a semicolon, we know that the bytes we have stored so far represent the station name.
- We can then start looking for newline character
- Continue with the iteration
- If it is not a newline character, store the byte somewhere, continue to next byte.
- If it is a newline character, we know that the bytes we have stored so far represent the temperature.
- We can then parse the station name and temperature from the bytes we have stored.
- Start looking for next entry, go back to 1.
To store the bytes, we can allocate a fixed-size buffer for each. From the challenge repo's readme
we know that we can store the station name in 100 bytes and the temperature in 5 bytes. We can allocate the respective amount of bytes by using
Buffer.alloc(n).
const NEW_LINE_CHARACTER = '\n'.charCodeAt(0);
const SEMICOLON_CHARACTER = ';'.charCodeAt(0);
const LOOKING_FOR_SEMICOLON = 0;
const LOOKING_FOR_NEWLINE = 1;
let state = LOOKING_FOR_SEMICOLON;
let stationBuffer = Buffer.alloc(100); // Allocate 100 bytes buffer to store station name
let tempBuffer = Buffer.alloc(5); // Allocate 5 bytes buffer to store temperature
let stationBufferIndex = 0;
let tempBufferIndex = 0;
stream.on('data', (chunk) => {
for (let i = 0; i < chunk.length; i++) {
const byte = chunk[i];
if (state === LOOKING_FOR_SEMICOLON) {
if (byte === SEMICOLON_CHARACTER) {
state = LOOKING_FOR_NEWLINE;
} else {
stationBuffer[stationBufferIndex] = byte;
stationBufferIndex += 1;
}
} else if (state === LOOKING_FOR_NEWLINE) {
if (byte === NEW_LINE_CHARACTER) {
const temp = Number(tempBuffer.toString('utf-8', 0, tempBufferIndex)) * 10;
const stationName = stationBuffer.toString('utf-8', 0, stationBufferIndex);
const existing = aggregations.get(stationName);
if (!existing) {
aggregations.set(stationName, {
min: temp,
max: temp,
sum: temp,
count: 1
});
} else {
existing.min = Math.min(existing.min, temp);
existing.max = Math.max(existing.max, temp);
existing.sum += temp;
existing.count += 1;
}
state = LOOKING_FOR_SEMICOLON;
stationBufferIndex = 0;
tempBufferIndex = 0;
} else {
tempBuffer[tempBufferIndex] = byte;
tempBufferIndex += 1;
}
}
}
})
After this improvement, the whole process now finishes in 2m35.389s; a ~2.2x speedup from the baseline implementation. Pretty good start!
Let's look at the flamegraph again to see if there are other parts that we can improve.
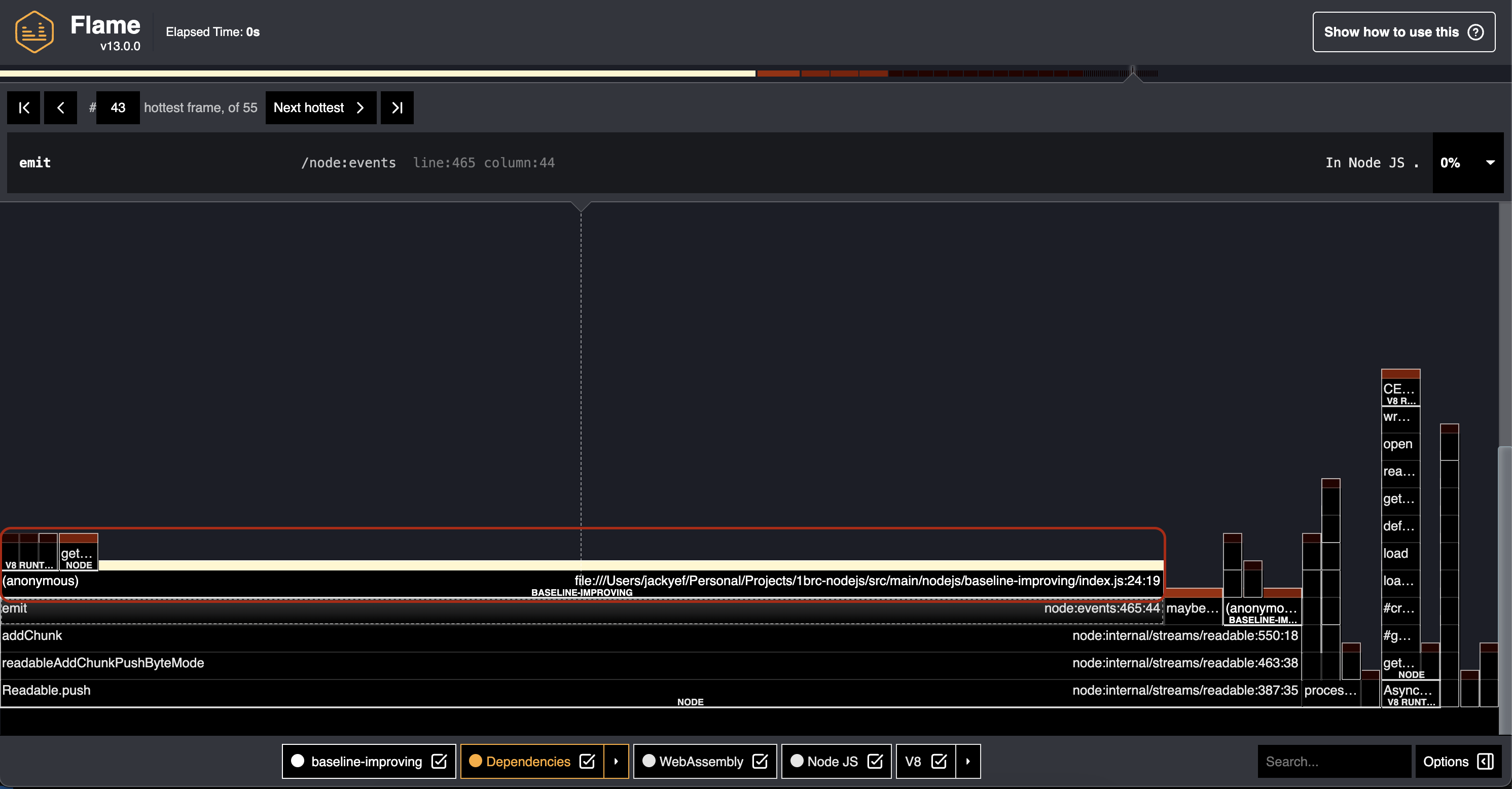
Hmm, this is tricky. There isn't any particular block on the top stack that is very wide. At the 2nd-level though, we see there is
one long block of index.js:24:19. In this case, this is the callback function we are passing to stream.on('data', (chunk) => {}).
Looking at the code, most of the lines are pretty straightforward. One possible part that could be slow is the conversion
from Buffer to station name and temperature.
const temp = Number(tempBuffer.toString('utf-8', 0, tempBufferIndex)) * 10;
const stationName = stationBuffer.toString('utf-8', 0, stationBufferIndex);
The conversion from Buffer to string is a pretty low-level implementation in Node.js, so we can't really optimize it further.
There isn't really a way to avoid this conversion either, so let's leave that for now.
The conversion to Number() is an interesting one though. On the one hand, it is a pretty low-level implementation, but perhaps
we can write a faster implementation specific to the limited constraints of the challenge.
Faster Buffer to number conversion
We know that the temperature can only be represented in 5 bytes. We also know there is always going to be one number behind the decimal point. Therefore, we may be able to iterate through each byte to calculate the value. The steps would be:
- Iterate through each byte, starting from the last one
- Initialize
sum = 0 - If the byte:
- Is a representation of the
.character, skip it. - Is a representation of the
-character, multiplysumby-1. - else, add the value of the byte to
summultiplied by10^i, whereiis the count of numbers we encountered up to this point.- The value of the byte can be calculated by subtracting the value of
0character from the byte.
- The value of the byte can be calculated by subtracting the value of
- Is a representation of the
const DOT_CHARACTER = '.'.charCodeAt(0);
const MINUS_CHARACTER = '-'.charCodeAt(0);
const ZERO_CHARACTER = '0'.charCodeAt(0);
function specificNumberConversion(buffer, lastIndex) {
let value = 0;
let pow = 0;
for (let i = lastIndex; i >= 0; i--) {
if (buffer[i] !== DOT_CHARACTER) {
if (buffer[i] === MINUS_CHARACTER) {
value *= -1;
} else {
value += (buffer[i] - ZERO_CHARACTER) * (10 ** pow++);
}
}
}
return value;
}
And we can replace the Number() conversion with this function:
const temp = specificNumberConversion(tempBuffer, tempBufferIndex - 1);
With this improvement, I was getting 1m44.210s, a pretty sizable improvement! We are now at ~3.3x speedup from the baseline implementation.
There are probably some other places for minor improvements, but I think this is a good place to start parallelizing the work to
take advantage of processors with multiple cores.
Parallelizing work
Node.js is single-threaded, but we can still take advantage of multiple cores by using the node:worker_threads module.
Since we know that the amount of work is probably fairly evenly distributed, we can use a naive approach by splitting the file
by the number of cores we have and processing each part in parallel. The general idea is as follows:
- The main thread calculates the split points
- The main thread spawns worker threads and passes the split points to each worker
- Each worker reads and parses the part of the files assigned to them
- Each worker aggregates the data
- Each worker sends the aggregated data back to the main thread
- Main thread combines the data from each worker and prints the result
We will start by structuring our code as follows:
import * as wt from 'node:worker_threads';
if (wt.isMainThread) {
// We will calculate split points here and distribute the work to worker threads
} else {
// This is inside the worker thread
// We can put the file streaming code we had before here
}
Let's focus on the main thread first. To be able to split the file evenly, we will need to know the file size and the amount of
cores we have at our disposal. We can use the node:os and node:fs/promises modules to get this information.
// Main thread
import * as os from 'node:os';
import * as fsp from 'node:fs/promises';
const THREADS_COUNT = os.cpus().length;
const splitPoints = [];
const fileName = process.argv[2];
const fileHandle = await fsp.open(fileName, 'r'); // Open file in read-only mode
const totalBytes = (await fileHandle.stat()).size;
Since we are splitting the file by the number of cores we have, we can calculate the split points by dividing the total bytes by the number of cores.
const maxBytesPerThread = Math.ceil(totalBytes / THREADS_COUNT)
We then find the nearest newline character from that point. This ensures that the part each worker is working on ends at a newline character.
Since we know each entry can only be at most 105 bytes, taking into account ; and \n, we can just read 107 bytes from the file.
const chunkSize = 107;
const bufferForReadingFile = Buffer.alloc(chunkSize);
let bytesRead = 0;
while (true) {
bytesRead += maxBytesPerThread;
if (bytesRead >= totalBytes) {
splitPoints.push(totalBytes)
fileHandle.close()
break;
}
// Zero-fill the buffer to start from a clean slate
bufferForReadingFile.fill(0)
await fileHandle.read(bufferForReadingFile, 0, chunkSize, bytesRead);
const newlineIndex = bufferForReadingFile.indexOf(newline)
splitPoints.push(bytesRead + newlineIndex + 1)
}
We can now start spawning workers and pass the file name and the split points to each worker.
import { fileURLToPath } from 'node:url';
// __filename refers to the current module.
const __filename = fileURLToPath(import.meta.url); // Required when working with ESM
const workers = [];
for (let i = 0; i < THREADS_COUNT; i++) {
const worker = new wt.Worker(__filename, {
workerData: {
fileName,
start: i === 0 ? 0 : splitPoints[i - 1],
end: splitPoints[i] || totalBytes
}
});
workers.push(worker);
}
The main thread should listen for messages from each worker. Once the last worker has finished, we can terminate the workers and start printing the result.
let finishedWorker = 0;
workers.forEach(worker => {
worker.addListener('message',
(workerResults) => {
finishedWorker += 1
// Merge the results
workerResults.forEach((workerData, key) => {
const masterData = aggregations.get(key)
if (!masterData) {
aggregations.set(key, workerData)
} else {
masterData.min = Math.min(masterData.min, workerData.min);
masterData.max = Math.max(masterData.max, workerData.max);
masterData.sum += workerData.sum;
masterData.count += workerData.count;
}
})
worker.terminate();
if (finishedWorker === THREADS_COUNT) {
printCompiledResults(aggregations)
return
}
}
);
});
The worker thread is just doing all the things we have previously, but instead of reading the whole file, it should only read the part assigned to it.
// Worker thread
const { fileName, start, end } = wt.workerData;
const stream = fs.createReadStream(fileName, {
start,
end,
});
And once the worker finishes, instead of printing out the result, we want it to notify the main thread with the aggregated data.
stream.on('end', () => {
stream.close();
wt.parentPort.postMessage(aggregations);
});
That's it! With this implementation, I was able to finish the challenge in 0m11.210s, a ~30x speedup from the baseline implementation.
The M4 Pro I am using has 14 cores, but the performance increment we are getting from our previous implementation is not ~14x, but ~9x instead.
This is likely due to the fact that not all the cores are equal (10 of them are high-performance cores and 4 of them are high-efficiency cores).
Some other factors are also probably in play, like the overhead of spawning workers, passing results, and the fact that we are reading from the same file.
Closing
| Step | Time taken | Speedup |
|---|---|---|
| Baseline | 5m41s | 1x |
| Work with bytes, not strings | 2m35s | 2.2x |
| Specialized number conversion | 1m44s | 3.3x |
| Parallelization, 14 cores (10P/4E) | 11s | 30x |
My actual process of trying to improve the implementation was not as straightforward as this blog post makes it out to be. I tested out different things, like:
- creating my own implementation of JS
Map()that occupies a block of shared memory viaSharedArrayBuffer, and have all workers read and write to it. This turned out to be not that fast due to the overhead of waits and locks of atomic operations. - doing
Buffer.prototype.slice()instead of manually assigning bytes to a pre-allocated Buffer size (e.g.:Buffer.alloc(100)). This turned out to be slower due to the overhead of creating the view of the buffer.
These detours taught me valuable lessons but are intentionally excluded here to keep the focus on the core concepts. This blog post aims to be more focused as to not overload readers with non-essential information.
While further optimizations are certainly possible, I am satisfied with the current results. Hopefully, this post has provided you with practical insights into approaching performance challenges in Node.js and incrementally refining your solutions. My key takeaways from this journey include:
- Profiling is helpful to avoid guesswork
- Working with bytes and integers tends to be faster than working with strings and floats
- Most built-in functions in Node.js are already plenty fast, but there could be opportunity to optimize for specific cases depending on the constraints we have
- Write your code in a way that would make it easy to be parallelized if we decide to take advantage of multiple cores later on
Thanks for following along—may your next performance optimization challenge be as rewarding as this one!